






Скажите «та». А теперь «да». Попробуйте прочувствовать особенности артикуляции в том и в другом случае. В чем разница?
Сложный вопрос? На самом деле нет. Дело не в положении губ или языка, а в так называемом времени начала озвончения — интервале между началом движения языка, с одной стороны, и колебания голосовых связок — с другой. Граница лежит примерно на уровне 40 миллисекунд: если интервал больше, англоговорящий человек услышит «та», если меньше, то «да».
Поразительно, но вы никогда не услышите третьего варианта: только «та» или «да». Неважно, какова разница между интервалами у двоих говорящих: важно лишь, превышают эти интервалы 40 мс или нет. У одного время начала озвончения может составлять 80 мс, у другого 50 мс, но в обоих случаях получится «та». Стоит одному говорящему оказаться по другую сторону границы, разница в 10 мс станет значимой: на 45 мс это будет еще «та», а на 35 мс — уже «да». Удивительно, но факт.
Последнее время интернет пестрит подобными увлекательными фокусами, демонстрирующими дихотомию нашего восприятия. Вспомнить хотя бы аудиозапись, на которой одни слышали «Янни», а другие — «Лорел». Или платье, которое кому-то казалось сине-черным, а кому-то бело-золотым. В обоих случаях, как с «та» и «да», люди разбились на два лагеря, и все были готовы поручиться, что их вариант — единственно верный.
Наш мозг — машина категоризации, непрерывно упрощающая и структурирующая гигантские объемы неоднозначной информации в попытке осмыслить окружающий мир. Это одна из его важнейших задач: благодаря этой способности мы с первого взгляда понимаем, змея перед нами или палка.
Категоризация имеет смысл, если обладает двумя свойствами. Во-первых, она должна быть обоснованной: нельзя произвольно делить на классы однородную группу предметов. Обоснованные категории, как сказал бы Платон, это составные части природы — скажем, те же палки и змеи. Во-вторых, категоризация должна быть полезной: каждая категория должна быть наделена важной для вас характеристикой. Отличать змей от палок, например, необходимо для собственной безопасности.
Вроде бы все понятно. Вот только в бизнесе мы зачастую создаем и используем необоснованные и/или бесполезные категории, что может привести к серьезным ошибкам при принятии решений.
Взять хотя бы типологию Майерс — Бриггс — инструмент личностной оценки, который, как указывают издатели, используется для принятия решений в более чем 80% компаний из списка Fortune 500. В зависимости от того, какой из двух ответов на 93 вопроса выбрал сотрудник, его причисляют к одной из 16 категорий. Но проблема в том, что эти ответы нужно тщательно анализировать. Как люди их дают: опираясь на факты или ощущения? Многие наверняка скажут: «По ситуации». Но разве это нормально для серьезного теста? Респонденты вынуждены каждый раз примыкать к тому или иному лагерю, выбирая варианты, которые, возможно, сочли бы неподходящими для себя при повторном тестировании. Все ответы суммируются, и на сотрудника навешивается ярлык: он не интроверт, а экстраверт, ориентирован на результат, а не на процесс. Все эти категории совершенно безосновательны. Пользы от теста тоже нет: по типу личности нельзя предсказать ни успех в работе, ни удовлетворенность ею.
Отчего же в таком случае типология Майерс — Бриггс столь популярна? Оттого, что категориальное мышление заставляет нас верить в иллюзии.
Склонность все классифицировать может привести к четырем проблемам. Она способна заставить нас обобщать составные части категории, считая их более однородными, чем они есть; преувеличивать различия между членами различных категорий; дискриминировать одни категории и превозносить другие и коснеть в своих убеждениях, воспринимая созданную единожды структуру как незыблемую.
Обобщение
Разделяя сущности на виды, мы представляем себе их усредненные образы. Увы, из-за этого мы зачастую игнорируем множество вариаций, существующих в рамках каждого вида.
Миф о целевом потребителе. Гарвардский исследователь Тодд Роуз в своей книге «Долой среднее!» рассказывает, что в 1945 году одна из кливлендских газет провела конкурс на «типичную» женскую фигуру. Незадолго до этого ученые измерили и усреднили все части женского тела. Редакторы газеты использовали эти обобщенные данные как «норму», которой должна соответствовать победительница. Свои мерки на конкурс прислали 3864 участницы. Как вы думаете, сколько из них оказались близки к средним величинам по всем параметрам? Ни одна. Люди настолько отличаются друг от друга, что соответствовать усредненным показателям хотя бы по нескольким критериям одновременно практически невозможно.
То же можно сказать и о потребителях. Задумайтесь, что происходит во время сегментирования аудитории — стандартного занятия маркетологов. Цель этого процесса — разделить потребителей на категории и найти среди них потенциальных клиентов, то есть выделить категорию, заслуживающую особого внимания и стратегической приоритетности.
Сегментирование аудитории начинается, как правило, с опроса потребителей — им задают вопросы об их поведении, желаниях и демографических характеристиках. Затем при помощи алгоритма кластеризации респонденты подразделяются на группы по схожести ответов. Такой анализ редко позволяет выявить явно дифференцированные категории. Тем не менее, вместо того чтобы задуматься о валидности созданных кластеров, маркетологи переходят к следующим стадиям процесса — выведению средних показателей, профилированию и созданию портрета целевой аудитории.
Именно так рождаются категории вроде «мам на минивэнах». Проведя исследование, маркетолог обнаруживает интересный кластер, в котором, допустим, 60% респондентов — женщины, их средний возраст — 40 с небольшим, среднее число детей у них — 2,75. Глядя на эти цифры, легко отойти от конкретных данных и начать фантазировать о типичном клиенте именно с такими параметрами — о маме на минивэне.

Подобные ярлыки заставляют нас забыть о том, что любая категория неоднородна. В 2011 году ученые дважды показали участникам исследования девять силуэтов женщин с равномерно увеличивающимся индексом массы тела. В первый раз у силуэтов не было подписей (см. рис. 1), а во второй их подписали: «Анорексия», «Норма» и «Ожирение» (см. рис. 2).

При каждом просмотре участники должны были оценить увиденное по различным критериям. Изображения в обоих случаях были идентичны, но их восприятие разнилось. Например, если силуэты 7 и 9 были помечены как страдающие ожирением, участники утверждали, что эти женщины обладают похожими качествами и ведут схожий образ жизни. То же касалось «нормальных» силуэтов 4 и 6.
Сегменты, с которыми работает большинство компаний, так же неоднозначны, как и типы женских фигур. Потребители из одного сегмента часто ведут себя по-разному. Чтобы снизить влияние обобщения, аналитикам и менеджерам стоит задаваться вопросом: насколько вероятно, что два клиента из разных кластеров окажутся более схожими, чем два клиента из одного кластера? Скажем, каков шанс, что вкусы в одежде «мамы на минивэне» окажутся ближе к вкусам не другой «мамы на минивэне», а «мамы-оригиналки»? Зачастую этот шанс ближе к 50%, чем к 0%.
Эффект сита. Обобщение может исказить решение о найме. Представьте себе, что вы отвечаете за подбор кадров. Вы разместили объявление о вакансии и получили 20 резюме. Вы отсеиваете кандидатов, сравнивая их технические навыки, и приглашаете на собеседование пятерых лучших.
Технические навыки этих пятерых заметно разнятся, но в дальнейшем это не слишком влияет на ваш вердикт: вы уже отобрали лучших по этому критерию и условно считаете их равными. Категориальное мышление ограничило ваш выбор, и дальше вы принимаете решение, оценив на собеседовании социальные навыки соискателей: обаяние, коммуникабельность и т. д. Конечно, все эти качества важны, но главным для многих должностей остаются технические навыки, а отсеивание мешает проверить их.
Аномалии финансовых инвестиций. Обобщение происходит и на финансовых рынках. Инвесторы условно классифицируют активы по размеру (с маленькой или большой капитализацией), отрасли (скажем, энергетика, здравоохранение), местонахождению и т. д. Такое ранжирование помогает им продраться через бесконечное количество вариантов инвестиций, но в то же время приводит к неэффективному — в плане рисков и окупаемости — вложению капитала. Например, в эпоху пузыря доткомов, в конце 1990-х, люди много и быстро инвестировали в интернет-компании, которые порой, кроме названия, ничто не связывало с новыми технологиями. Эта ошибка дорого обошлась множеству инвесторов. Еще пример: когда организация попадает в список S&P 500, ее акции начинают расти или падать в цене одновременно с акциями других фирм из списка, даже если к этому нет никаких предпосылок.
Преувеличение
Мысля категориями, вы раздуваете различия между ними. Это может привести к стереотипному восприятию людей из других групп, установке произвольных критериев при принятии решений и некорректным выводам.
Групповая динамика. Преувеличение может иметь серьезные последствия, ведь оно искажает наше мнение о членах социальных и политических групп. Исследования показывают, что люди с противоположными политическими убеждениями склонны переоценивать полярность взглядов друг друга.
Как вы думаете, кто больше озабочен, например, социальным неравенством — либералы или консерваторы? Если ваш ответ «либералы», то вы правы. В среднем они действительно придают этой проблеме больше значения, чем консерваторы. Тем не менее существуют консерваторы, больше тревожащиеся по поводу неравенства, чем многие либералы. Предположим, мы опросим на улице двух случайных прохожих — голосующего за консерваторов и за либералов. Какова вероятность того, что первый сочтет социальное неравенство более значимой темой, чем второй? Намного ближе к 50%, чем может показаться. Усредненные значения маскируют неизбежные совпадения между группами, раздувая различия — зачастую кажущиеся. Хотя средние показатели говорят о другом, многие консерваторы беспокоятся о неравенстве больше либералов.
Если вы американский либерал, вы наверняка убеждены: все консерваторы выступают против абортов, контроля над оборотом оружия и социальной поддержки населения. Если вы консерватор, то не сомневаетесь: все либералы мечтают об открытых границах и универсальной системе здравоохранения. На самом же деле убеждения людей, безусловно, варьируются в широчайших пределах.
Преувеличение, вызванное категориальным мышлением, особенно опасно сегодня, в век больших данных и профилирования клиентов. Например, известно, что Facebook* сортирует пользователей по идеологии («умеренные», «консерваторы», «либералы»), опираясь на историю поиска, и предоставляет эту информацию рекламодателям. У последних может сложиться впечатление, что разница между выделенными категориями существеннее, чем на самом деле. Парадоксальным образом это способно усилить реальные различия, ведь каждой категории будет предлагаться соответствующий рекламный контент. Именно это, видимо, произошло в 2016 году во время президентских выборов в США и кампании Brexit: Facebook* выдавал «консерваторам» и «либералам» разные материалы, дополнительно раскалывая общество.
Многие организации борются с последствиями такого преувеличения. Успех во многом зависит от того, способны ли представители разных отделов плодотворно сотрудничать. Однако если вы мыслите категориями, то можете недооценивать эффект от подобного взаимодействия. Вероятно, вы думаете, что оно не имеет смысла, люди не найдут общего языка, ведь аналитики — технари, не понимающие сути бизнеса, а маркетологи, наоборот, знают, как он функционирует, но не умеют работать с данными. Кстати, это одна из основных причин провала аналитических проектов.
Принятие решений. Преувеличение исподволь влияет и на принимаемые руководителями решения. Только представьте себе: тренеры НБА на 17% чаще меняют стартовую пятерку, если в предыдущей игре команда оказалась близка к победе (счет — 100:101), а не к поражению (счет — 100:99). Всего два очка разницы! При этом редкий тренер сменит состав при счете 100:106, однако озаботится заменой при 100:108, хотя разница та же самая. Проигрыш от выигрыша отличается качественно, а не количественно, и мы не смотрим на спортивные результаты как на некий континуум.
Каждый раз, когда мы принимаем решение, установив для себя некое пороговое значение, мы преувеличиваем небольшие различия. После финансового кризиса 2008 года правительство Бельгии решило спасти от банкротства компанию Fortis, входящую в группу BNP Paribas. В результате в собственности правительства оказались миллионы акций BNP Paribas. По данным бельгийской газеты De Standaard, в конце января 2018 года, когда цена этих акций превысила €67, руководство страны решило продать их, как только она достигнет €68. Этого не произошло: цена упала и сегодня составляет лишь €44.
Никто в правительстве, конечно, не мог предугадать подобного падения. Ошибка состояла не в неточности прогноза, а в решении продать все сразу и только в случае превышения конкретного порога цен. Разумнее было бы продать часть акций по одной цене, часть по другой и т. д.
Статистическая значимость. По мере того как поведенческая экономика и аналитика данных приобретают все большую популярность, компании все чаще прибегают к А/В-тестированию, чтобы оценивать свою эффективность. Одна из причин — такие тесты просто проводить и анализировать: нужно создать две версии ситуации, различающиеся одним фактором, поставить одну группу участников в условия версии А, другую — в условия версии В, а затем сравнить их поведение. Разница между группами, конечно, будет всегда — во многом за счет элемента случайности. Поэтому, чтобы определить, значима ли разница и свидетельствует ли она о влиянии нужного фактора, необходимо применять статистические методы. Что они показывают? Вероятность того, что разница того же масштаба могла бы наблюдаться, если бы фактор был несущественным. Эта вероятность известна как р-значение. Чем ближе р-значение к нулю, тем с большей уверенностью вы можете утверждать, что разница в проведенном тесте вызвана именно исследуемым фактором. Но как понять, достаточно ли она близка к нулю?
В 1925 году британский статистик и генетик Рональд Фишер принял волевое решение считать пороговым показатель 0,05. С тем же успехом он мог выбрать, например, 0,03; более того, Фишер рекомендовал каждый раз заново определять этот порог в зависимости от специфики конкретного исследования. Однако на это редко обращают внимание: уже почти 100 лет целые научные дисциплины слепо считают 0,05 волшебной границей, отделяющей сигнал от шума. Та же практика усвоена и бизнесом.
Это большая проблема. Если А/В-тестирование выдает р-значение, равное 0,04, фактор решают изменить, а если 0,06 — оставить неизменным, несмотря на отсутствие значимого различия между 0,04 и 0,06! Что еще хуже, многие экспериментаторы регулярно проверяют накопленные данные на статистическую значимость и перестают собирать их, как только р-значение падает ниже 0,05. Подобное поведение существенно повышает вероятность того, что несущественный фактор будет признан существенным, то есть бессмысленное вмешательство в ситуацию сочтут успешным. Недавнее исследование по анализу действий экспериментаторов, использующих популярную онлайн-платформу для А/В-тестирования, показало: большинство из них пользуются этим сомнительным приемом, повышая долю ложноположительных результатов с 33 до 42%.
Дискриминация
Распределив имеющиеся сущности по категориям, вы естественным образом начинаете отдавать предпочтение одним из них. Однако уделять недостаточно внимания «нелюбимым» категориям опасно.
Чрезмерное таргетирование. Представьте себе, что вы директор по цифровому маркетингу розничной компании, торгующей необычными предметами интерьера. Вы сегментировали аудиторию и выявили целевую категорию со следующими характеристиками: работающие мужчины 18—34 лет с творческой профессией в сфере моды, маркетинга или медиа, получающие средний доход. Ваш бюджет на цифровую рекламу — $10 тыс., и вы рассматриваете три варианта. 1) Без таргетинга — реклама будет предложена с равной вероятностью всем пользователям Facebook* и будет стоить 40 центов за клик. 2) С полным таргетингом — рекламу покажут только целевой аудитории, и это обойдется в 60 центов за клик. 3) С частичным таргетингом — половина бюджета пойдет на целевую аудиторию, половина — на всех пользователей соцсети; стоимость — 48 центов за клик.
Какой план выбрать? Наверное, второй или третий, потому что они позволяют прицельно метить в аудиторию, верно?
Нет. Наверняка лучше выбрать первый вариант — самый широкий охват. Почему? Широкий таргетинг часто окупается лучше узкого. Исследователи обнаружили, что онлайн-реклама повышает вероятность покупки буквально на долю процента. Если без рекламы шанс, что человек приобретет ваш продукт, составляет 0,10%, то с ней вырастет до 0,13%. Для целевых клиентов положительный эффект рекламы может оказаться чуть больше, но чаще всего он не оправдывает цену за клик. Увы, в погоне за целевой аудиторией маркетологи регулярно недополучают доход от остальных потребителей.
Facebook* пытается донести до клиентов-рекламодателей информацию о том, что широкий охват выгоднее узкого таргетинга. Он приводит в пример пивной бренд, всегда рекламировавший свою продукцию мужчинам. Перейдя на цифровые медиаплатформы, бренд сумел сузить таргетинг и был этому рад. Однако результаты его кампаний значительно ухудшились, и бренд стал терять в выручке. Все проанализировав, он понял, что существенную долю его потребителей составляли женщины. Расширив таргетинг и креативный посыл, он сразу же увидел изменения к лучшему.
Оценка лояльности клиентов. Дискриминация мешает интерпретировать данные. Преподавая аналитику данных, мы часто спрашиваем студентов, кто из них слышал об индексе потребительской лояльности (NPS) и чьи фирмы используют этот показатель. Всегда поднимается лес рук, и это понятно. После того как Фредерик Райхельд представил эту концепцию в HBR («The One Number You Need to Grow», декабрь 2003 г.), NPS быстро стал — и остается — одним из важнейших показателей производительности компаний.
Что же такое NPS и как он работает? Организация просит клиентов (или сотрудников) отметить на шкале от 0 до 10 вероятность того, что они рекомендуют ее родным или друзьям (0 означает «ни в коем случае», 10 — «безусловно»). На основе ответов потребителей делят на три категории: критики (0—6 баллов), нейтральные покупатели (7—8) и сторонники (9—10). NPS рассчитывается как процент сторонников минус процент критиков. Если среди ваших клиентов 60% сторонников и 10% критиков, ваш NPS равен 50.
Использование NPS во многом оправдано: индекс прост как в использовании, так и для понимания. К тому же он помогает избежать преувеличения — или, как писал в знаменитой статье сам Райхельд, «инфляции оценок, часто поражающей традиционные системы измерения удовлетворенности клиентов, при которой любой отзыв хоть на волосок лучше нейтрального считается положительным».
Все это прекрасно. Однако система NPS сама основана на преувеличении, с которым, по идее, призвана бороться. Например, клиенты с оценкой 6 намного ближе к 7, чем к 0, но их причисляют к критикам, а не к нейтралам. Иными словами, даже небольшая разница в баллах между категориями становится значимой для определения индекса, а внутри категории даже существенная разница считается незначимой.
NPS выявляет еще одну проблему категориального мышления: он игнорирует людей с «нейтральными» оценками. Сопоставим два полярных результата: компанию, у которой 0% критиков и 0% сторонников, и компанию, у которой 50% критиков и 50% сторонников. NPS в обоих случаях будет одинаков, но очевидно, что клиентские базы этих организаций существенно различаются и работать с ними следует по-разному.
Предвзятое толкование корреляций. Категориальное мышление также может помешать вам толковать информацию. Представьте себе, что вы руководите сервисным центром. Вы уверены, что удовлетворенность сотрудников влияет на удовлетворенность клиентов, и решаете исследовать этот вопрос. Спустя некоторое время кадровые аналитики присылают вам визуализацию результатов (см. рис. 1).
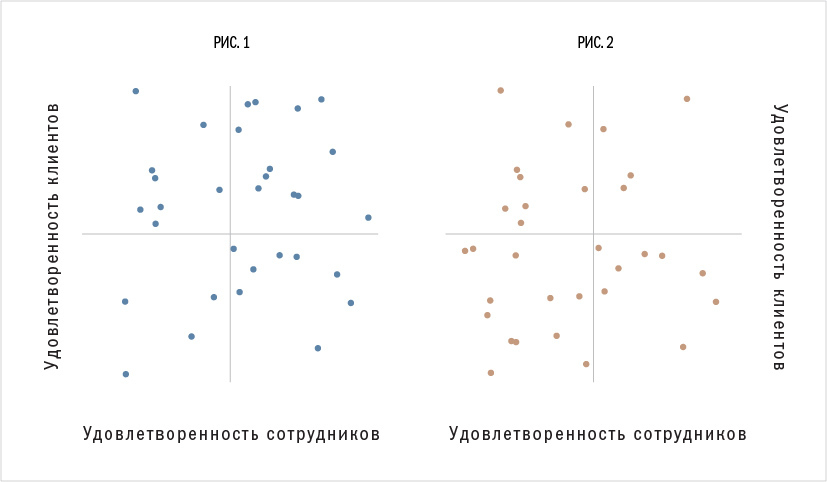
Как бы вы оценили уровень зависимости между удовлетворенностью тех и других? Большинство считает его умеренно высоким.
А что, если бы результаты были другими (см. рис. 2)? Как бы вы оценили уровень такой зависимости?
Обычно утверждают, что он значительно более низкий или вообще нулевой. Однако на самом деле взаимосвязь в обоих случаях почти одинаковая. Рисунки идентичны, только на втором восемь точек из верхнего правого квадранта перенесены в нижний левый.
Почему же людям кажется, что на первом рисунке зависимость сильнее? Они привыкли считать правый верхний квадрант самым важным. На рис. 1 они видят много удовлетворенных сотрудников с удовлетворенным клиентами и заключают, что связь довольно сильна. На рис. 2 они видят мало удовлетворенных сотрудников с удовлетворенными клиентами и заключают, что связь слаба. Отсюда мораль: не уделяя должного внимания всем категориям, нельзя точно определить взаимозависимость между переменными.
Косность
Категории зажимают нас в тиски определенного взгляда на мир. Они дают нам ложное ощущение, будто мы вскрыли истинное положение вещей, а не сами придумали, как его трактовать. Как прекрасно сказал экономист Джон Кейнс, «проблема не в том, чтобы найти новые идеи, а в том, чтобы освободиться от старых».
В 1950-х годах основным производителем велосипедов в Штатах была Schwinn Bicycle Company. Она ориентировалась на молодежь, поставляя на рынок тяжелые хромированные велосипеды с большими колесами: подростки с удовольствием катались на таких по району. Однако к 1970-м рынок заметно трансформировался: велоспорт приобрел популярность среди взрослых, а им понадобились более легкие и быстрые железные кони. Schwinn не успела вовремя среагировать на изменение спроса, и американцы переключились на производителей из Европы и Японии. Легендарная компания начала медленный и мучительный путь к забвению — и все оттого, что ослепленная десятилетиями успешных продаж, она не заметила на рынке тектонических сдвигов.
Инновации. Инновации и отход от категориального мышления идут рука об руку. Многие фирмы, чтобы повысить эффективность работы, прибегают к категоризации. Они закрепляют обязанности за сотрудниками, сотрудников за отделами и т. д. Такие дисциплинарные границы имеют определенный смысл, но при этом они имеют и цену. Бизнес-проблемы будущего никогда не укладываются в те рамки, которые создавались для решения проблем прошлого. Люди, мыслящие исключительно в пределах существующих категорий, не способны порождать ничего оригинального, поскольку не могут по-новому комбинировать привычные элементы.
Здесь можно вспомнить исследование ученых из Университета Торонто, которые в 2016 году предложили примерно 200 участникам собрать из деталек Lego инопланетянина. Некоторым выдали детали, рассортированные по группам, другие получили их в несистематизированном виде. Третья команда, которая должна была оценить креативность полученных фигурок, признала «несистематичных» пришельцев более оригинальными.
Закостеневая, категории могут тормозить инновации и в другом отношении — затрудняя нестандартное использование объектов или идей. Это называется «функциональная фиксированность». Если вам дать саморез и гаечный ключ и попросить закрепить саморез в стене, как вы будете действовать? Вполне возможно, что само устройство ключа наведет вас на мысль ухватить им шляпку самореза и попытаться ввернуть его в стену — что вряд ли получится. Самый эффективный подход — просто вбить ключом саморез в стену, как молотком, — может не прийти вам в голову.
Защита от категориального мышления
Как же уберечься от опасностей, которые таит в себе категориальное мышление? Мы предлагаем систему из четырех шагов.
1. Повышайте осознанность. Мы все мыслим категориями — это неизбежно. Но при принятии решений следует помнить, что такое мышление приводит к упрощениям, искажениям, предвзятости и ложному ощущению, что «все просто и понятно». Чтобы избежать этих ловушек, компании должны объяснять сотрудникам, что нюансы и сложность — это нормально, и учить их работать в условиях неопределенности. Принимая любые решения, нужно спрашивать себя: обоснована ли и полезна ли моя категоризация?
2. Старайтесь анализировать данные непрерывно. Предотвратить ошибки, связанные с привычкой мыслить категориями, можно, если постоянно исследовать происходящее. Но это умеют не все компании. Например, когда речь идет о сегментации, они часто поручают аналитику специализированным фирмам, а затем некорректно интерпретируют приобретенную информацию. Эту проблему относительно легко решить. Обладая минимальными навыками, можно проверять обоснованность выявленных сегментов с помощью хорошо зарекомендовавших себя метрик. Всем организациям, чьи маркетинговые исследования или стратегическое планирование предполагают сегментирование аудитории, стоит внедрить такие метрики и обучать сотрудников работе с ними. Это отличная возможность повысить компетентность персонала и получить конкурентное преимущество.
3. Контролируйте критерии принятия решений. Многие компании начинают действовать только после преодоления некоего произвольно выбранного порога в континууме явлений. У этого подхода есть два минуса.
Во-первых, он повышает риски. Представим себе фирму, которая с помощью маркетинговых исследований пытается спрогнозировать шансы нового продукта на успех. Она может принять решение запускать новинку, если масштабный опрос покажет, что потребительские оценки выше определенного уровня, — или если в эксперименте р-значение окажется ниже магического показателя 0,05. Но поскольку разница между «чуть выше» и «чуть ниже» нужного порога ничтожно мала, велик шанс, что компания неверно оценит свое положение относительно этой цифры — из-за особенностей выборки или неточности в сборе данных. Незначительное отклонение в ту или иную сторону может определить судьбу продукта — не факт, что счастливую (это поняло правительство Бельгии, не дождавшееся нужной цены акций). В подобной ситуации намного разумнее применять поэтапный подход. Тем же бельгийцам стоило бы действовать по ситуации, а не ждать достижения некоего предельного значения.
Во-вторых, произвольно назначенный порог мешает развитию. Предположим, компания заявила: если она не выполнит план по выручке, то проведет организационную реформу. Если выручка будет немного ниже запланированной, руководство сочтет, что пора принимать меры, и запустит реформу. Если же фирма с трудом, но дотянет до цели, она решит, что пока волноваться не стоит, и продолжит работать в обычном режиме — хотя в обоих случаях показатели будут почти идентичны.
Чтобы такого не происходило, мы рекомендуем пересматривать критерии принятия решений во всей организации. Вы наверняка удивитесь, узнав, как часто люди ориентируются на некие предельные значения. Иногда без этого действительно не обойтись, но зачастую есть альтернативные пути, позволяющие обеспечить себе еще одно конкурентное преимущество.
4. Проводите регулярные тренинги по «антикосности». Даже если следовать трем предыдущим принципам, риск косности никуда не девается. Чтобы снизить его, устраивайте мозговые штурмы — анализируйте свои базовые представления о происходящем в отрасли. Не устарели ли ваши данные о потребительских предпочтениях? Не изменились ли нужды и желания клиентов?
Эффективный путь к инновациям — размышление об отдельных компонентах, составляющих существующие категории, и изобретение для них новых задач. Например, автомобили доставляют людей из точки А в точку В, а почтальоны доставляют почту из точки А в точку В. Верно?
Да, но, мысля так, вы наверняка упускаете любопытные возможности. Это осознала Amazon: она решила, что машины могут быть точками приема корреспонденции, и ввела для своих премиальных клиентов в США новую услугу — доставку посылок в багажник. В Нидерландах почтовая служба PostNL заново рассмотрела обязанности своих сотрудников и поняла, что по пути к адресатам они могут фотографировать сорняки, помогая оценивать эффективность обработки территории гербицидами. Так у почтальонов появилась новая важная задача, которую никогда не удалось бы изобрести в рамках категориального мышления.
Категории помогают нам осмысливать этот мир и доносить наши идеи до окружающих. Но в стремлении систематизировать все и вся мы часто находим категории там, где их нет. Это искажает наше видение мира и заставляет принимать неверные решения. Когда-то бизнесу удавалось работать, несмотря на подобные ошибки. Но сегодня, в эпоху революции данных, мы не преуспеем, если не позаботимся о снижении ущерба от категориального мышления.


