






Уже более 250 лет главными факторами экономического роста остаются технологические инновации. Важнейшими из них становятся те, которые экономисты называют технологиями широкого применения, — в их числе паровая машина, электричество и двигатель внутреннего сгорания. Каждая такая инновация порождает волны сопутствующих разработок и открывает новые возможности. Так, двигатель внутреннего сгорания непосредственно «породил» автомобиль, самолет, бензопилу, газонокосилку, а косвенно — сетевую розничную торговлю, торговые центры, сквозное складирование, новые сети поставок и, если вдуматься, даже пригороды. Такие разные компании, как Walmart, UPS и Uber, научились использовать технологии для создания новых прибыльных бизнес-моделей.
В наши дни важнейшей технологией широкого применения стал искусственный интеллект и, в частности, машинное обучение — то есть способность машины улучшать свои результаты без участия человека. За последние несколько лет машинное обучение стало намного эффективнее и доступнее. Создаваемые сегодня системы способны самостоятельно овладевать навыками решения задач.
Почему это важно? По двум причинам. Во-первых, мы, люди, осознаем далеко не все, что умеем: мы не можем толком объяснить, каким образом узнаем соседа в лицо или выбираем ход в игре го. До появления машинного обучения эта неспособность осмыслять свои умения мешала нам их автоматизировать. А теперь это возможно.
Во-вторых, системы машинного обучения часто превосходят нас как своих учителей. Они достигают сверхчеловеческих результатов в самых разных сферах, включая выявление мошенничества и диагностику заболеваний. Эти блестящие «ученики» приходят во многие отрасли — и от них можно ждать колоссальной отдачи.
Искусственный интеллект способен вывести бизнес на качественно новый уровень. Хотя он уже используется в тысячах компаний по всему миру, его главные возможности пока не раскрыты. В ближайшие 10 лет отдача от внедрения ИИ резко возрастет: производство, розничная торговля, транспорт, финансовые услуги, здравоохранение, юриспруденция, реклама, страхование, развлечения, образование и прочие отрасли развернут свои процессы и бизнес-модели в сторону машинного обучения. Сегодня сложности связаны в основном с управлением, внедрением и бизнес-воображением.
Как это случалось со многими другими технологиями, на ИИ изначально возлагали слишком большие надежды. Машинное обучение, нейросети и другие варианты этой технологии часто упоминают в бизнес-планах, не понимая их истинных возможностей. Если какой-нибудь сайт знакомств объявит, что подбирает пары с помощью ИИ, это не сделает его эффективнее — но поможет привлечь средства. В этой статье мы попытаемся разобраться, каков истинный потенциал ИИ, где его стоит применять и что этому мешает.
На что способен ИИ сегодня?
Термин искусственный интеллект был предложен в 1955 году Джоном Маккарти, профессором математики из Дартмута. Годом позже Маккарти провел знаменитую конференцию, посвященную этой теме. С тех пор (возможно, отчасти из-за яркого названия) вокруг ИИ множатся фантастические слухи и домыслы. В 1957 году экономист Герберт Саймон предположил, что в ближайшее десятилетие компьютер выиграет у человека в шахматы (в действительности это произошло через 40 лет). В 1967 году когнитивист Марвин Минский заявил: «Проблема создания “искусственного интеллекта” в целом будет решена при нынешнем поколении». Оба великих ученых ошиблись. Стоит ли удивляться, что громкие слова о будущих прорывах ИИ нередко вызывают скепсис?
Для начала разберемся, что уже умеет ИИ и как быстро он развивается. Значительного прогресса пока удалось достичь в двух широких областях: восприятии и понимании. В первом случае наибольшие подвижки произошли, пожалуй, в технологиях распознавания речи. Они еще далеки от совершенства, но и в нынешнем виде их используют миллионы людей — вспомним Siri, Alexa или Google Assistant. Текст, который вы сейчас читаете, изначально был надиктован компьютеру и распознан им: это быстрее, чем набирать его вручную. Исследование, проведенное стэнфордским специалистом в области вычислительных систем Джеймсом Лэндеем и его коллегами, показало, что в среднем наговаривать текст на телефон оказывается в три раза быстрее, чем печатать на нем. Количество ошибок распознавания за последнее время снизилось с 8,5 до 4,9%. Заметьте: говоря «за последнее время», я имею в виду не «за последние 10 лет», а «с лета 2016 года»!
Качество распознавания образов тоже существенно улучшилось. Возможно, вы заметили, что Facebook* и разные приложения теперь узнают лица ваших друзей на фото и предлагают их отметить. Есть приложения, позволяющие опознать почти любую птицу в дикой природе. Технология распознавания образов может даже заменить офисные пропуска. Системы наблюдения вроде тех, что установлены в беспилотных автомобилях, еще недавно при обнаружении пешеходов допускали одну ошибку на 30 кадров (при скорости съемки около 30 кадров в секунду) — а теперь они ошибаются не чаще одного раза на 30 миллионов кадров. Вероятность ошибки при распознавании изображений из базы ImageNet, где собраны миллионы самых разных фотографий, в 2010 году составляла более 30%, а к 2016-му у лучших систем она стала ниже 4% (см. врезку «Щенок или маффин?»).
В последние годы, с внедрением нового подхода на основе «глубоких» нейросетей, возможности ИИ расширяются особенно быстро. Визуальные образы все еще распознаются не идеально — но ведь и мы, люди, не всегда сразу узнаем мордочку щенка (или можем увидеть ее там, где ее нет).
Что касается достижений ИИ в области понимания и решения задач, здесь машины уже обыгрывают лучших игроков в покер и го — эксперты не ожидали таких результатов раньше следующего десятилетия. Команда DeepMind (Google) с помощью систем машинного обучения повысила эффективность охлаждения ЦОД более чем на 15% — и это уже после того, как охлаждение оптимизировали эксперты! Компания Deep Instinct, работающая в сфере кибербезопасности, использует ИИ для поиска вредоносных программ, а PayPal предотвращает с его помощью финансовые махинации. Система на основе технологий IBM автоматизирует обработку исков в сингапурской страховой компании, а система от разработчика информационных платформ Lumidatum дает рекомендации по улучшению обслуживания клиентов. Десятки компаний используют машинное обучение для планирования биржевых операций, а банки — для принятия решений о выдаче кредитов. Amazon применяет машинное обучение, чтобы оптимизировать складские запасы и персонализировать предложения. Infinite Analytics разработала одну систему машинного обучения для международного ритейлера (расчеты кликабельности рекламы помогают размещать ее оптимальным образом), а другую — для бразильского интернет-магазина (клиенты стали быстрее находить нужные товары). Первая увеличила окупаемость рекламы втрое, а вторая повысила годовую прибыль на $125 млн.
Системы машинного обучения не только заменяют старые алгоритмы, но и превосходят людей в решении многих задач. Они еще далеки от совершенства, но их доля ошибок при работе с ImageNet (около 5%) уже не выше, чем у людей. В распознавании голоса, даже на фоне шума, они почти не уступают человеческому уху. Это открывает колоссальные возможности для трансформации рабочих мест и экономики в целом. Обходя человека в решении тех или иных задач, системы машинного обучения получают путевку в жизнь. Например, Aptonomy (производитель дронов) и Sanbot (производитель роботов) автоматизировали работу служб охраны с помощью продвинутых систем видеонаблюдения. Affectiva, компания-разработчик ПО, использует такие решения для распознавания эмоций (радости, удивления, гнева) во время фокус-групп. Enlitic и ряд стартапов в области систем глубокого обучения сканируют с их помощью медицинские снимки для обнаружения рака.
Эти достижения впечатляют — но системы ИИ все еще имеют ограниченное применение. Например, блестящие результаты их работы с огромной базой ImageNet не всегда повторяются на другом материале, ведь освещение, угол съемки, разрешение и фон могут быть очень разными. Есть и более важный момент. Мы можем восторгаться способностью системы понимать китайскую речь и переводить ее на английский, но мы не ждем от нее распознавания китайских иероглифов — не говоря уже о знании пекинских ресторанов. Если человек хорошо выполняет какую-то работу, логично предположить, что он справится и со смежными задачами. Но системы машинного обучения «натасканы» лишь на конкретные задачи и, как правило, неспособны обобщать знания. Ошибочное мнение, будто узкоспециальная информация, выдаваемая компьютером, говорит о его широких познаниях, — вероятно, главный источник ложных и завышенных ожиданий от ИИ. Мы еще очень далеки от создания машин с высоким общим интеллектом.
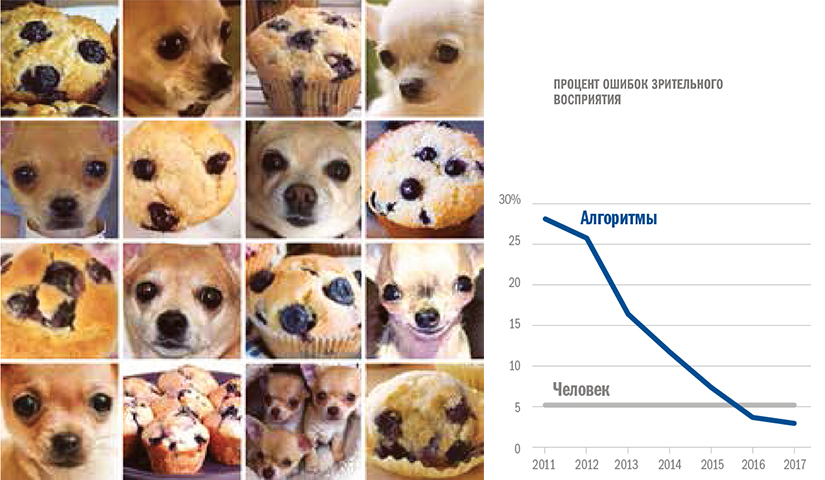
<b>Щенок или маффин? Прогресс в распознавании образов</b><br><span style="background-color: transparent;">Машины хорошо научились различать похожие изображения</span>
Что такое машинное обучение
Важно понимать, что машинное обучение в корне отличается от создания обычного ПО: машины не программируются сразу на конкретный результат, а постепенно учатся на примерах. Это принципиальное новшество. В последние 50 лет прогресс в информационных технологиях и их применении сводился к кодированию знаний и процедур и внедрению их в машины. Сам термин «программный код» предполагает, что знания из головы разработчика переводятся (кодируются) в понятную машине форму. У этого подхода есть существенный недостаток: многие знания и умения мы обретаем неосознанно и сами не можем толком разложить их по полочкам. Например, практически невозможно написать исчерпывающую инструкцию, по которой кто-то другой сможет научиться ездить на велосипеде или узнавать друзей в лицо.
Иными словами, все мы знаем намного больше, чем можем объяснить. Этот феномен известен как «парадокс Полани» — в честь философа и ученого-энциклопедиста Майкла Полани, сформулировавшего его в 1964 году. Парадокс Полани не только не позволяет нам эксплицировать все наши умения, но и препятствует созданию машины с интеллектом. Все это долгое время ограничивало сферу эффективного применения машин в экономике.
Однако машинное обучение преодолевает этот парадокс. С приходом второй волны второго века машин программы стали учиться на примерах и использовать структурированную обратную связь для решения ранее неразрешимых проблем (таких, как распознавание лиц в классическом примере Полани).
Разновидности машинного обучения
Искусственный интеллект и машинное обучение обретают разные формы, но наибольшие успехи в последние годы были достигнуты в области контролируемого машинного обучения, при котором машина получает множество примеров верных ответов на тот или иной вопрос. Этот процесс почти всегда предполагает соотнесение набора вводных данных с набором выходных данных. Например, вводными данными могут быть изображения животных, а выходными — названия этих животных: собака, кошка, лошадь. Другой пример — звуки аудиозаписи на входе и напечатанные слова на выходе: «да», «нет», «привет», «пока» (см. врезку «Системы контролируемого обучения»).
Успешные системы сначала используют обучающие базы данных с тысячами или даже миллионами примеров, каждому из которых присвоен верный ответ. Затем система начинает сама анализировать новые примеры. Если обучение пройдет удачно, она будет предсказывать ответы с высокой точностью.
Алгоритмы, во многом обеспечившие этот успех, основаны на подходе с использованием нейросетей — его называют глубоким обучением. Алгоритмы глубокого обучения имеют важное преимущество перед ранними поколениями технологий машинного обучения: они эффективнее работают с огромными объемами данных. Старые системы совершенствовались по мере накопления опыта — но лишь до определенного момента, после которого новые данные уже не повышали качество ответов. По словам Эндрю Ына, одного из главных экспертов в этой области, у глубоких нейросетей нет этого недостатка: чем больше данных они получают, тем точнее результат. Некоторые крупные системы обучаются более чем на 36 млн примеров. Конечно, такие объемы данных требуют серьезных вычислительных мощностей — крупнейшие системы часто работают на суперкомпьютерах или устройствах с особой архитектурой.
Где и когда можно применять системы глубокого обучения? В любой ситуации, когда есть множество данных о каких-то действиях и нужно спрогнозировать их последствия. Джефф Уилки, директор по производству Amazon, говорит, что контролируемое обучение уже во многом заменило в компании алгоритмы фильтрации на основе памяти, ранее применявшиеся для персонализации предложений. В ряде случаев классические алгоритмы для складского учета и оптимизации поставок были заменены более эффективными и надежными системами машинного обучения. JPMorgan Chase внедрила такое решение для анализа договоров о коммерческих кредитах: работа, занимавшая у специалистов 360 тыс. часов, теперь выполняется в считаные секунды. Кроме того, сегодня глубокое машинное обучение помогает диагностировать рак кожи. И это лишь несколько примеров.
Промаркировать набор данных и использовать его для машинного обучения относительно несложно — поэтому контролируемые системы встречаются чаще, чем неконтролируемые (по крайней мере пока). Системы неконтролируемого обучения учатся как бы сами по себе. Пример такой системы — мы сами: мы получаем большую часть знаний о мире (например, учимся различать деревья) почти без специального обучения. Но создать машину, способную учиться таким образом, чрезвычайно сложно.
Когда (и если) мы создадим надежные решения для неконтролируемого обучения, нам откроются уникальные возможности. Машины смогут по-новому взглянуть на наши проблемы и помочь нам открыть неизвестные пока закономерности — в распространении болезней, колебаниях биржевых котировок, покупательском поведении и т. д. Задумавшись о таких перспективах, Ян Лекун, руководитель исследований ИИ в Facebook* и профессор Нью-Йоркского университета, сравнил контролируемое машинное обучение с глазурью на торте, а неконтролируемое — с самим тортом.
Еще одно перспективное направление — обучение с подкреплением. На этом принципе основаны системы, научившиеся играть в видеоигры Atari и в го. Он же помогает оптимизировать энергопотребление ЦОД и разрабатывать торговые стратегии для фондового рынка. Роботы компании Kindred используют машинное обучение для идентификации и сортировки незнакомых им объектов, что ускоряет перемещение потребительских товаров в центрах дистрибуции. Создавая такие решения, разработчики задают текущее состояние системы и цель, описывают допустимые действия и компоненты среды, ограничивающие результаты каждого из действий. С помощью допустимых действий система должна сама найти способ максимально приблизиться к цели. Такие системы хороши там, где человек может поставить задачу, но не знает точно, как ее решить. Например, Microsoft использовала обучение с подкреплением для выбора заголовков новостей на MSN.com, «поощряя» высокими баллами те, по которым кликали чаще. Система стремилась набрать максимальные баллы в рамках заданных правил. Разумеется, обучение с подкреплением приблизит вас только к тем целям, которые вы поощряете, — а они могут не вполне отвечать вашей конечной цели (например, увеличению пожизненной ценности клиента), поэтому здесь важно максимально четко поставить задачу.

<span style="background-color: transparent;"><b>Системы контролируемого обучения</b></span><br><span style="background-color: transparent;">По мнению пионеров этого направления Тома Митчелла и Майкла Джордана, основной прогресс здесь достигнут в извлечении выходных данных из вводных. Вот несколько примеров</span><br><br><span style="background-color: transparent;"></span>
Машинное обучение в действии
Исследователи отмечают три положительных момента, важных для организаций, которые хотят использовать машинное обучение уже сегодня. Во-первых, все больше людей овладевает навыками работы с ИИ. Специалистов и экспертов в этой сфере пока не хватает, но над удовлетворением спроса активно работают университеты и онлайн-курсы. Лучшие из них, такие как Udacity, Coursera и fast.ai, не просто знакомят с азами — с их помощью мотивированный студент может научиться самостоятельно развертывать корпоративные системы машинного обучения. Помимо обучения собственных сотрудников, компании могут найти опытных экспертов на онлайн-платформах вроде Upwork, Topcoder и Kaggle.
Второй положительный момент — возможность купить или арендовать необходимые алгоритмы и технику для систем ИИ. Google, Amazon, Microsoft, Salesforce и другие компании предоставляют облачный доступ к мощным инфраструктурам машинного обучения. Острая конкуренция между этими гигантами ведет к тому, что компаниям, желающим испытать или внедрить машинное обучение, будет доступно все больше недорогих технологий.
Наконец, третий и, возможно, самый недооцененный позитивный факт состоит в том, что на первом этапе использования машинного обучения вам вовсе не нужны гигантские массивы данных. Да, эффективность большинства систем растет с объемом данных, и кажется логичным, что выиграют компании с максимальной базой. Это так — но только если «выиграть» значит для вас «завоевать глобальный рынок одной функции» (например, таргетинга рекламы или распознавания речи). Однако если ваша цель — улучшить показатели, то получить достаточный для этого объем данных не составит труда.
Так, сооснователь Udacity Себастьян Трун заметил, что некоторым специалистам по продажам намного лучше других удается отвечать на вопросы клиентов в чате. Трун и его магистрант Зейд Энам поняли, что логи рабочих чатов представляют собой, по сути, наборы данных для контролируемого машинного обучения. Чаты, завершившиеся продажей, были помечены как удачные, а прочие — как неудачные. Зейд использовал эти данные для выявления шаблонов удачных ответов на вопросы клиентов, а затем предложил эти шаблоны другим продажникам, чтобы они могли улучшить свою работу. После 1000 циклов машинного обучения показатели отдела продаж выросли на 54%, а его сотрудники стали обслуживать вдвое больше клиентов за единицу времени.
Аналогичный подход практикует стартап WorkFusion. Он помогает компаниям автоматизировать работу бэк-офиса — например, оплату международных счетов и осуществление крупных транзакций между финансовыми институтами. До недавних пор эти сложные процессы не автоматизировались: они требуют определенной экспертизы и интерпретации, к тому же необходимые данные могут каждый раз выглядеть по-разному («Как понять, о какой валюте речь?»). ПО от WorkFusion отслеживает фоновые рабочие процессы и использует данные о действиях сотрудников, чтобы научиться классифицировать («Этот счет в долларах. Этот в иенах. Этот в евро...»). Как только система обучится, ей доверяют соответствующую процедуру.
Машинное обучение вызывает сдвиги на трех уровнях: это задачи и рабочие обязанности, бизнес-процессы и бизнес-модели. Пример изменений в задачах и обязанностях — использование систем машинного зрения для обнаружения раковых клеток: это экономит время рентгенологов, позволяя им сосредоточиться на других важных задачах, общении с пациентами и взаимодействии с другими врачами. Изменение бизнес-процессов можно наблюдать на примере Amazon, внедрившей роботов и алгоритмы оптимизации складского учета на основе машинного обучения. А чтобы, например, использовать все преимущества систем, персонализирующих рекомендации музыки и фильмов, придется пересмотреть бизнес-модель. Вместо того чтобы продавать отдельные треки, пытаясь угадать вкусы потребителя, новая модель будет предусматривать подписку на целую персонализированную «радиостанцию» с музыкой, которая предположительно должна понравиться клиенту, даже если он ее никогда не слышал.
Заметим, что системы машинного обучения не могут полностью заменить какую-либо должность, процесс или бизнес-модель. Чаще всего они лишь дополняют работу человека (что не делает их менее ценными). Новое разделение труда не предполагает полной передачи функций машине. Обычно из десяти этапов процесса автоматизировать удается один или два — и это позволяет человеку уделять больше внимания остальным. Система поддержки продающих чатов в Udacity не свелась к созданию бота, который сам бы вел все беседы, — она просто подсказала продажникам, как улучшить работу. Люди остаются главными и при этом повышают производительность. Такой подход целесообразнее, чем попытки создать машину, которая все сделает за нас. С ним люди получают больше удовольствия от работы, а клиенты — больше пользы.
Разработка и внедрение новых комбинаций технологий, человеческих навыков и капитала требуют творческого подхода и планирования. Машинам это не по зубам — так что в век ИИ на первый план выходят менеджмент и предпринимательство.
Риски и ограничения
Вторая волна второго века машин принесла новые риски. В частности, системы машинного обучения часто имеют низкую интерпретируемость: человеку трудно понять, как они принимают решения. Глубокие нейросети могут содержать сотни миллионов связей, каждая из которых влияет на результат, а потому точно объяснить логику полученного прогноза невозможно. В отличие от нас, машины еще не научились рассказывать истории. Они не всегда могут дать отчет, почему конкретного кандидата не взяли на работу или почему конкретному пациенту прописано то или иное лекарство. Удивительно, что, едва начав преодолевать парадокс Полани, мы столкнулись с его новой версией: теперь уже машины знают больше, чем могут объяснить.
За этим скрывается три риска. Во-первых, машины могут иметь скрытые «пристрастия» — не из-за ошибки создателя, а из-за особенностей данных, на которых они обучались. Например, если система учится отбирать кандидатов для собеседования на основе данных о решениях, принятых рекрутерами, она может перенять их расовые, гендерные, этнические или другие предпочтения. Они могут не восприниматься машиной как явное правило, но все же учитываться наряду с тысячами других факторов.
Во-вторых, в отличие от традиционных систем, построенных на четких логических правилах, нейросети работают не с абсолютной, а со статистической истиной. Это не позволяет рассчитывать, что система сработает во всех случаях — особенно в ситуациях, не предусмотренных обучающими данными. Плохая верифицируемость может стать проблемой при принятии критически важных решений — например, при управлении АЭС.
В-третьих, если система машинного обучения ошибается (что неизбежно), очень трудно понять, что пошло не так, и исправить ошибки. Базовая структура, определяющая решения, чрезвычайно сложна, и если условия, на которых обучалась система, вдруг изменятся, решения станут неоптимальными.
Все эти риски весьма реальны, однако конечной целью для ИИ должен быть не идеальный результат, а выбор лучшей из доступных альтернатив. В конце концов, мы, люди, тоже пристрастны, совершаем ошибки и не всегда можем объяснить, как пришли к решению. Преимущество систем машинного обучения в том, что они со временем совершенствуются и при одних и тех же вводных данных выдают один и тот же результат.
Значит ли это, что возможности ИИ и машинного обучения безграничны? Их достижения в сфере восприятия и понимания уже позволяют доверять им немало задач — от вождения автомобиля до прогнозирования продаж и принятия решений о найме и продвижении. Мы полагаем, что вскоре ИИ наверняка достигнет сверхчеловеческой эффективности в большинстве из этих областей. Тогда что же этим технологиям не под силу?
Иногда приходится слышать, что «искусственный интеллект никогда не сможет понять людей с их эмоциями, комплексами, лукавством, непоследовательностью — он для этого слишком прямолинеен и равнодушен». Мы не согласны с этим. Системы машинного обучения вроде применяемых компанией Affectiva уже не хуже, а то и лучше нас способны распознавать эмоции по голосу и выражению лица. Другие системы могут распознать блеф даже у лучших игроков в покер и победить их один на один в очень сложной версии этой игры — безлимитном техасском холдеме. Чтение мыслей — тонкая работа, но в ней нет никакой магии. Она требует восприятия и понимания — а это как раз те сферы, где машинное обучение уже на высоте и продолжает прогрессировать.
Говоря о пределах возможностей ИИ, стоит вспомнить замечание Пабло Пикассо: «Компьютеры бесполезны. Они могут только давать ответы». Как показывают последние прорывы в области машинного обучения, компьютеры вовсе не бесполезны — однако и слова великого художника не утратили актуальность. Техника призвана отвечать на вопросы, но не задавать их. А значит, предприниматели, новаторы, ученые, деятели искусства и другие люди, ставящие перед человечеством новые вопросы и задачи, останутся незаменимыми.
Кроме того, есть огромная разница между пассивной оценкой чьего-то душевного состояния и активной работой по его улучшению. Системы машинного обучения неплохо справляются с первой задачей — но сильно уступают нам во второй. Люди — существа социальные, и убедить, мотивировать и вдохновить нас на подвиги, надавив на наши чувства сострадания, гордости, солидарности или стыда, могут только люди, но не машины. В 2014 году TED Conference и фонд XPrize объявили награду за «первый искусственный интеллект, который выйдет на эту сцену и выступит достаточно убедительно, чтобы аудитория аплодировала стоя». Сомневаемся, что эта награда найдет своего героя в обозримом будущем.
Мы полагаем, что в грядущую эпоху сверхмощных систем машинного обучения экспертам стоит искать точки приложения сил на пересечении двух областей: они должны выявлять проблемы, требующие решения, и убеждать людей в необходимости брать на вооружение ИИ и руководствоваться его подсказками в своих действиях. По сути, речь идет о лидерстве, которое во втором веке машин обретает особую важность.
Привычное разделение труда между человеком и машиной уходит в прошлое. Компании, стремящиеся сохранить статус-кво, будут все больше отставать от конкурентов, готовых и способных внедрить машинное обучение везде, где оно применимо, и эффективно сочетающих работу человека и компьютера.
Технологический прогресс в сфере ИИ вызывает тектонические сдвиги в деловой сфере. И вновь, как во времена появления паровой машины и электричества, выиграют не те, кто получит доступ к лучшим технологиям и наймет лучших разработчиков, а те, кто преодолеет инерцию и найдет принципиально новые способы применения технологий — а затем воплотит их в жизнь. Вероятно, бум машинного обучения породит совершенно иное поколение бизнес-лидеров.
Сегодня ИИ (и прежде всего машинное обучение) — важнейшая технология широкого применения. Решения на основе ИИ окажут непосредственное воздействие на бизнес и экономику и повлекут «сопутствующие» инновации. Компьютерное зрение, распознавание речи, интеллектуальное решение задач и другие возможности машинного обучения открывают путь новым продуктам и способам работы.
Некоторые эксперты заглядывают еще дальше. Гил Пратт, глава Исследовательского института Toyota, сравнил нынешний подъем технологий ИИ с кембрийским взрывом — появлением 500 млн лет назад огромного количества форм жизни. Тогда, как и сейчас, одной из главных новых возможностей стало зрение. Обретя его, животные стали лучше ориентироваться в пространстве, что способствовало взрывному росту числа видов и заполнению разных экологических ниш. Сегодня мы ждем появления множества продуктов, услуг, технологий, организационных форм — наряду с вымиранием устаревших явлений. Мы увидим истории успеха и краха.
И хотя сегодня сложно предсказать, какие именно компании добьются успеха в новых условиях, общий принцип ясен: выживут самые гибкие и легкие на подъем. Те, кто быстро замечает и использует новые возможности, получат все преимущества ИИ. Залог успеха — готовность экспериментировать и быстро учиться. Если современный менеджер не задумывается о внедрении машинного обучения, он плохо справляется с работой. В ближайшие 10 лет ИИ не заменит менеджеров — но менеджеры, использующие его, заменят тех, кто этого не делает.
Об авторах. Эрик Бриньолфссон (Erik Brynjolfsson) — директор Программы цифровой экономики при MIT, профессор теории управления Школы управления Слоуна при MIT, научный сотрудник Национального бюро экономических исследований. Эндрю МакАфи (Andrew McAfee) — старший научный сотрудник MIT, сооснователь Программы цифровой экономики при MIT.


