
читайте также

Призрак возвращается
Николай Александров
Так ли плохо, что таланты уходят к конкурентам?
Андрей Шипилов

Женщины в бизнесе: что изменилось за 30 лет
Уильям Скарборо

Как не попасть в ловушку сопереживания
Жаклин Картер, Марисса Эфтон, Расмус Хогард
читайте также




В одной из переговорных огромного здания штаб-квартиры Facebook* Хоакин Кандела пытается объяснить человеку со стороны, что такое искусственный интеллект. Кандела руководит группой прикладного машинного обучения — «локомотивом» развития ИИ, а значит, и всей компании. Тщательно подбирая слова, он рассказывает: «Смотрите, алгоритм машинного обучения — это, по сути, справочная таблица. В ней есть ключевые понятия — это вводные данные, например картинки; и их значения — определения для вводных данных, например “лошадь”. Допустим, у меня есть несколько примеров чего-то — скажем, фото лошадей. Я предлагаю алгоритму максимум таких фотографий. “Вот это лошадь. И это лошадь. И тут лошадь. И вот здесь тоже лошадь”. Алгоритм методично заносит их в таблицу. Затем, когда поступит новый пример (или я дам команду отслеживать новые примеры), алгоритм сравнит его со всеми предыдущими. На какие строки в таблице похож новый пример? И насколько похож? Он пытается решить: “Вот эта штука — лошадь ли она? Думаю, да”. Если он решает, что да, картинка попадает в группу “Это лошадь”, а если нет — в группу “Это не лошадь”. Таким образом к следующему разу у него будет больше данных для анализа.
Первый вопрос: как определить, достаточно ли новое изображение похоже на имеющиеся? Одна из задач машинного обучения — научить машину отличать значимые расхождения от незначимых. Второй вопрос: как быть, если таблица слишком разрослась и каждую новую картинку приходится сравнивать с кучей других? Еще одна задача — обобщение громадных объемов данных, чтобы не продираться через каждое фото. Эта функция позволяет прогнозировать очередное значение. В этом суть машинного обучения — быстро обобщать гигантскую таблицу с помощью особой функции. Вот о чем речь».
Разумеется, это еще не все — но уже хорошее начало для разговора об ИИ: так эта загадочная технология выглядит весьма наглядно, почти банально. Кандела не любит домыслов вокруг ИИ и старается говорить о нем как можно проще. Да, это мощная технология, но никакой магии в ней нет, и ее возможности не безграничны. Во время презентаций он любит показывать слайд с волшебником и фабрикой и объяснять аудитории: Facebook* видит в ИИ скорее фабрику, ведь «волшебники не масштабируются».
Искусственный интеллект и машинное обучение нужны Facebook* именно для быстрого масштабирования возможностей. Несколько лет назад в ее группе машинного обучения работало всего несколько человек — и каждый эксперимент занимал по нескольку дней. Сейчас, по словам Канделы, сотни сотрудников ежедневно проводят тысячи экспериментов. ИИ настолько врос в платформу компании, что ее продукты — ленту новостей, чаты, аккаунты — невозможно «очистить» от алгоритмов. Почти все, что видят и делают пользователи, основано на ИИ и машинном обучении.
Знать, как и почему Facebook* так активно применяет ИИ, полезно всем, кто готов инвестировать в алгоритмы. Конечно, многие решат, что с Facebook*, учитывая ее ресурсы, конкурировать бесполезно: она все равно найдет лучших специалистов и напишет лучшие алгоритмы. Но у Хоакина Канделы иное видение. Разумеется, в компании трудятся опытные разработчики, которые создают отличные алгоритмы. Эти программы способны «видеть» и фильтровать изображения. Они понимают беседы пользователей и могут реагировать на них. Они переводят общение с одного языка на другой. Они предугадывают, что вы захотите купить.
Но алгоритмы — не главная забота Канделы. Он создает особую мастерскую, где каждый сотрудник сможет с помощью ИИ достичь своей цели. Кандела строит ИИ-платформу для платформы Facebook*. Ею сможет воспользоваться любой — от опытного программиста до новичка.
Вот что ему удалось сделать — и вот о чем стоит задуматься другим.
«Союз»
Кандела долго работал в Microsoft Research, а в 2012 году пришел в рекламный отдел Facebook*. Здесь он в составе небольшой группы продолжал работу над алгоритмом ранжирования для оптимизации таргетинга.
По воспоминаниям Хоакина, унаследованный его командой код машинного обучения был «надежным, но не лучшим». Он сравнивает его с советским космическим кораблем «Союз» 1960-х годов — простым безотказным аппаратом, который продолжал использоваться, даже когда появились более совершенные модели: «На него всегда можно было положиться. Но он, конечно, не был новейшей сверточной нейросетью».
Возможно, вы подумали, что первым делом Кандела решил обновить алгоритм — заменить «Союз» более современным аппаратом. Вовсе нет. «Чтобы повысить эффективность, можно сделать три вещи, — объясняет он. — Либо изменить сам алгоритм и сделать его сложнее; либо добавить в него новые данные, чтобы существующий код работал более точно; либо ускорить эксперименты, чтобы быстрее получать результаты. Мы выбрали второй и третий путь, не меняя алгоритм».
Кандела называет это решение трудным. ИТ-специалисты, особенно ученые, обычно стремятся создавать новые или совершенствовать старые алгоритмы. Их цель — улучшить статистическую модель, а лучшая награда — цитирование в профильных журналах и авторитет среди коллег.
Чтобы поставить бизнес-результаты выше оптимизации статистической модели, таким профессионалам приходится наступать на горло собственной песне. Хоакин Кандела уверен, что многие компании совершают ошибку, бросая все силы на улучшение алгоритмов или нанимая разработчиков с таким опытом. Для компании надежный алгоритм, стабильно улучшающий бизнес-показатели, ценнее, чем суперновые статистические модели. Кандела уверен: настоящие прорывы в области алгоритмов случаются довольно редко — не чаще двух-трех раз в год. Если бы его коллеги бросались внедрять все новинки, их нелегко было бы окупить.
Он раз за разом повторяет свою мысль: главное — польза для бизнеса. Важно понимать, какую задачу компании вы решаете: «Порой мы ищем самый крутой алгоритм или людей, которые считают свои алгоритмы самыми продвинутыми, — хотя на самом деле нам нужны те, кто сумеет выжать максимум из любого алгоритма. Мне кажется, эта простая истина сегодня как-то подзабылась. Недавно я говорил с нашим специалистом по машинному обучению о том, как разные люди подходят к ИИ. И он мне сказал: “На самом деле никто не считает свои алгоритмы такими уж отличными”. Я подумал, что это, наверное, хорошая новость. Я не пытаюсь отговорить вас совершенствовать алгоритмы. Я лишь думаю, что намного лучше дать имеющимся системам больше полезных данных и ускорить эксперименты с ними».
Хоакин видит цель не в создании лучшего алгоритма для обработки естественного языка, а в развертывании такой системы, которая в ответ на вопрос пользователя к друзьям «Где бы тут перекусить?» порекомендует подходящий ресторан. Он не испытывает священного трепета перед алгоритмом компьютерного зрения, почти идеально распознающим объекты, — ему важна способность ИИ заметить, что вы публикуете фотографии пляжа, и помочь вам приобрести купальник.
Подход Канделы принес плоды: прибыль Facebook* от рекламы выросла. Группе прикладного машинного обучения предлагали статус централизованного подразделения компании. Хоакин дважды отказывался. «Я не верю, что люди сами потянутся к ИИ», — поясняет он. Нет смысла создавать решения в надежде, что другие оценят их и кинутся внедрять.
Однако он нашел, где применить свой опыт. Отказав ряду групп, Кандела стал сотрудничать с командой, занимавшейся лентой новостей. Затем он работал с коллективом, отвечавшим за Messenger. Его группа росла и включалась во все большее число проектов.
К 2015 году Хоакин понял, что группе пора стать отдельным подразделением, и задумался, как это лучше устроить. Он еще сомневался, что люди сами уверуют в ИИ, и переживал не столько о структуре отдела, сколько о том, как он будет взаимодействовать с другими подразделениями Facebook*. «Вы построили фабрику, производящую отличные штуки, но не предусмотрели в заборе ворота для их отгрузки? — смеется он. — Вот и наслаждайтесь сами своими штуками».
Только тогда, спустя три года после начала работы, Кандела решил обновить некоторые алгоритмы. (Кстати, и по сей день корабль, пристыкованный к Международной космической станции на случай экстренной эвакуации экипажа, — это очередная модификация «Союза».)
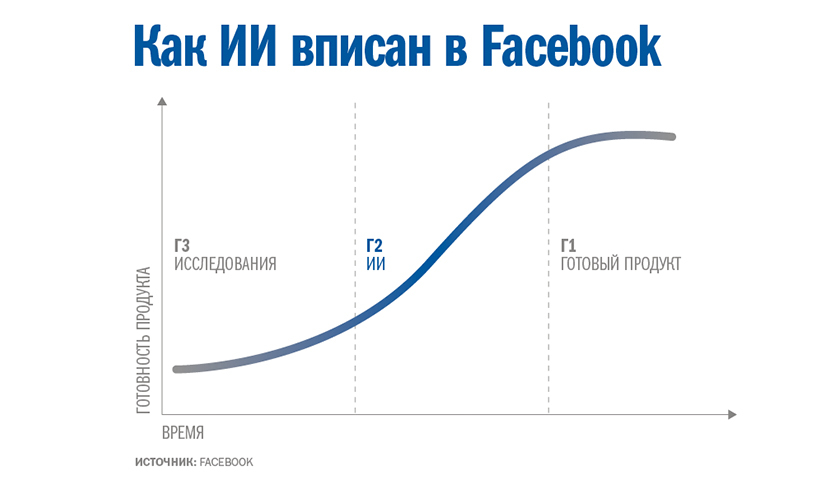
Г2
Хоакин Кандела рисует на маркерной доске процесс встраивания «фабрики ИИ» в состав Facebook*. По его словам, важнее всего было понять, на каком этапе разработки продукта лучше всего подключать ИИ. Он изображает график (см. врезку «Как ИИ вписан в Facebook*»).
Г3 (трехлетний горизонт планирования) — эпоха науки и НИОКР. Специалисты по анализу данных, работающие с ИИ, часто думают, что их место здесь: на этом этапе нужно доработать алгоритмы и найти новые способы обучения машин. Но Кандела не видит здесь свою команду по упомянутым выше причинам: отсюда слишком далеко до какой-либо пользы для бизнеса. Г1 (один год до запуска продукта) — время групп разработки продукта, имеющих дело непосредственно с лентой новостей, рекламой, Instagram*… Здесь ИИ тоже не нужен: модифицировать продукты, достигшие этого уровня, слишком сложно. Это все равно, что внезапно решить, что новый автомобиль, который уже собирают на конвейере, должен стать беспилотным.
Остается Г2 — период между наукой и продуктом, в который и подключается к работе группа прикладного машинного обучения. Она помогает внедрить в продукт научные достижения. Это экватор процесса: уже нет исследований ради научного интереса, но еще нет готовых решений. Идущий вверх график готовности продукта отражает динамику ситуации. Кандела указывает на Г2: «Здесь нельзя расслабиться и почивать на лаврах. Важно сразу нанимать самоотверженных людей, готовых к постоянному поиску. Добившись успеха, ты должен его закреплять. На этом пути неизбежны ошибки. Я считаю хорошим показателем частоту ошибок 50%».
Если ошибки случаются реже, Кандела начинает подозревать коллег в излишней осторожности или в решении задач, свойственных Г1 (доработке готового продукта). «Да, мы можем взять на себя такую задачу и выполнить ее — но это неправильно, потому что этим должны заниматься другие. Если у вас есть технология, из которой больше пользы для бизнеса сможет извлечь отдел рекламы, надо отдать ее отделу рекламы, а самим активнее работать над машинным обучением, прежде чем что-то станет продуктом».
Итак, команда Канделы не занимается ни изобретением новых статистических моделей, ни выпуском продукции. Эта фабрика профессионалов берет научные разработки у одних — и передает другим для создания продуктов (при этом ошибаясь в половине случаев).
Мы к вам — вы к нам
Границы между Г3, Г2 и Г1, конечно, размыты. В одних случаях группе Канделы приходится обращаться к исследованиям машинного обучения ради решения каких-то задач, в других — помогать создавать конечный продукт.
Особенно часто это случалось на заре существования отдела, когда многие коллеги толком не понимали, что такое ИИ и зачем он нужен. Например, однажды отделу пришлось разработать алгоритм перевода. Команда изучила принципы работы и пути улучшения подобных программ, понимая, что плохой перевод зачастую хуже, чем никакого.
«Сначала мы активно продвигали себя, — вспоминает Хоакин. — Но делали это ненавязчиво: не то чтобы мы подходили к отделу разработки и требовали, чтобы они использовали наши находки». Команда Канделы помогала в написании части кода продукта. Обращаясь, помимо основной работы, к научным изысканиям и к созданию продуктов, отдел машинного обучения тем самым демонстрировал свои возможности другим подразделениям.
В результате такого взаимодействия было создано рабочее решение — мгновенный перевод страниц сообществ на несколько языков. Вновь созданный отдел поучаствовал по своей инициативе еще в ряде проектов — и сегодня международная группа и другие продуктовые отделы Facebook* уже сами обращаются к нему, чтобы использовать ИИ в своей работе.
«Я пока не достиг того уровня, к которому стремлюсь, — признает Кандела. — Я бы хотел, чтобы все те, кто отвечает за продукты компании, ежеквартально встречались для обсуждения возможностей ИИ. В будущем, я уверен, так и будет. Но за последние два года отношение к нашему отделу в корне изменилось. Теперь, когда я иду по штаб-квартире и встречаю, скажем, сотрудника отдела видео или отдела Messenger, они меня останавливают и говорят: “Слушай, мы попробовали ваш код — так здорово! Похоже, из этого выйдет новый продукт”. Раньше такого не было».
Успех отдела машинного обучения поставил перед Хоакином Канделой новые задачи. Теперь, когда ИИ оказался нужен всем, его «фабрике» пора масштабироваться.
Слоеный пирог
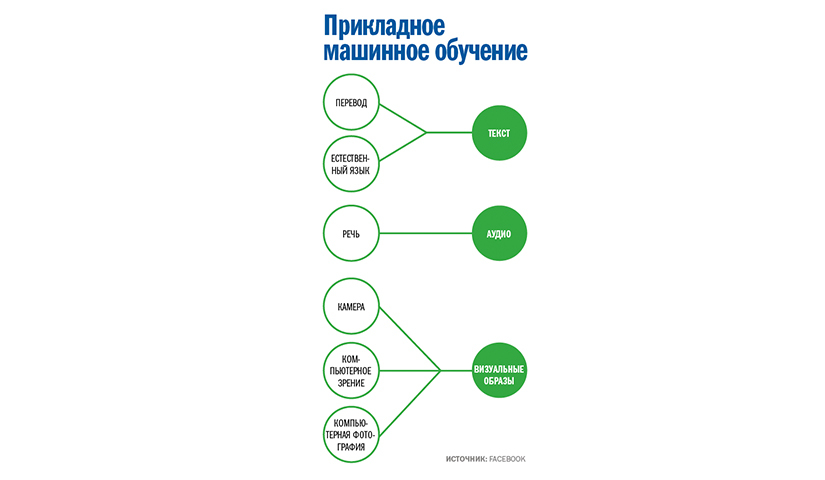
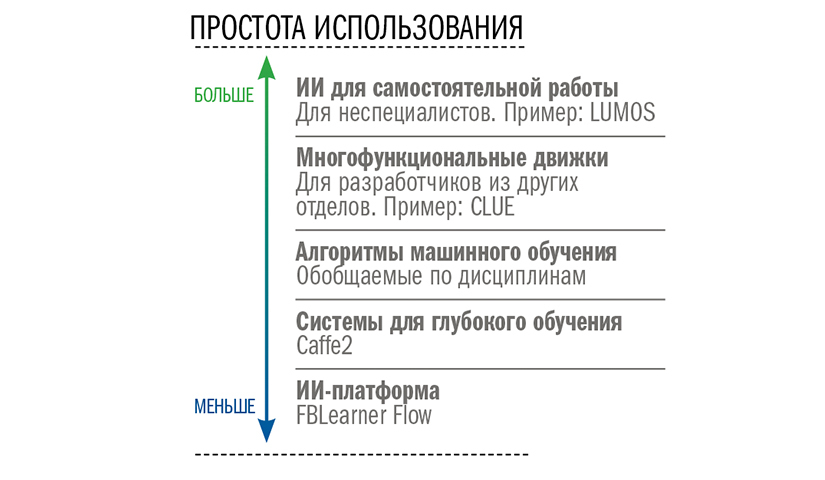
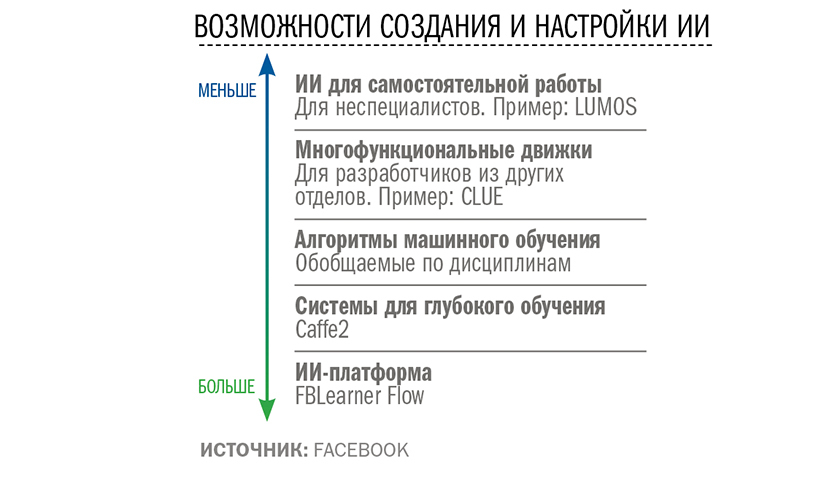
Расти, просто участвуя во всех проектах и нанимая все больше людей, неразумно. Кандела организовал все иначе. Для начала он разделил сотрудников по типам ИИ, над которыми они работали (см. врезку «Прикладное машинное обучение»).
Сформировались единые подходы: скажем, группа компьютерного зрения стала работать над всеми приложениями машинного обучения, предполагающими анализ изображений, и использовать наработки в новых проектах.
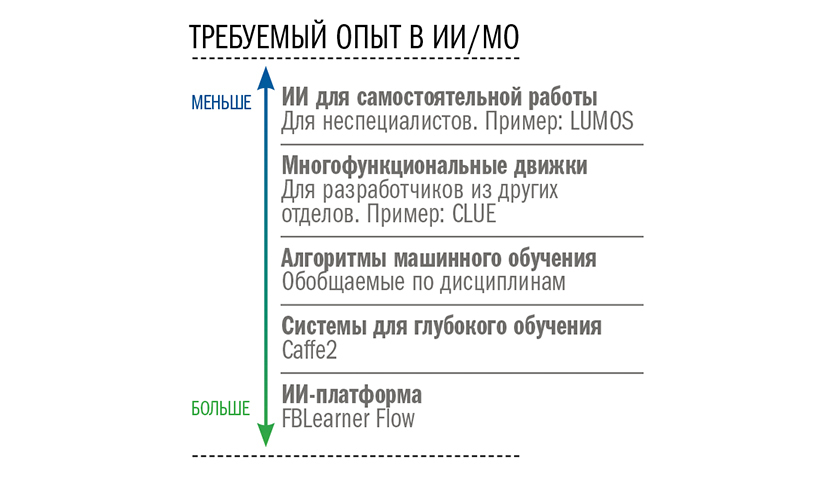
Затем последовал масштабный проект по созданию собственной ИИ-платформы для Facebook* — FBLearner Flow. Развернутые здесь алгоритмы может использовать кто угодно. Времязатратные процедуры настройки и проведения экспериментов автоматизированы, а все их результаты сохраняются и остаются общедоступными: по ним можно даже проводить быстрый поиск. Систему поддерживает серьезное аппаратное обеспечение, что позволяет одновременно проводить множество расчетов (более 6 млн в секунду). Цель — увеличить объемы и масштабы экспериментов (см. врезку на с. 47).
Система рассчитана на одновременную работу разных типов пользователей. Кандела убежден, что широкое внедрение и развитие ИИ невозможны без поощрения людей из других отделов к самостоятельному использованию технологии. Он создал, по его словам, «слоеный пирог» ИИ.
Нижние слои — забота его отдела: оптимизация основного движка (с упором на повышение эффективности, особенно для мобильных устройств) и работа с алгоритмами машинного обучения. Верхние слои — это инструменты, которые позволяют другим сотрудникам внедрять алгоритмы с минимальным участием специалистов по ИИ. «Важно понять, чтó можно дать в руки пользователям», — поясняет Кандела. Он создал ряд систем, которые разработчики из других отделов могут применять для создания и использования собственных моделей ИИ.
Рекомендации
Чтобы понять, как работает отдел Канделы и принцип «мы к вам — вы к нам», обратимся к ИИ, созданному для показа контента по текстовому запросу. Группа машинного обучения естественному языку разработала программу для распознавания переписки.
Сначала этот код использовался в чат-клиенте Messenger. Отдел Хоакина Канделы разработал статистические модели, а проектная группа — ситуации и типы «намерений» (то есть учебных задач для ИИ). Например, обучение ИИ понимать фразы типа «Посоветуйте мне лучший…» и разумно реагировать на них — это намерение.
Первые несколько намерений были развернуты в Messenger с помощью продукта M Suggestions. Если вы пишете другу «Встретимся через полчаса», M Suggestions может показать вам, скажем, предложения по каршерингу.
По мере того как инструменты для разработки моделей намерений совершенствовались и создатели продукта привыкали с ними работать, роль отдела Канделы сокращалась. К настоящему времени группа Messenger уже самостоятельно добавила в M Suggestions десятки новых намерений.
Но система обработки естественного языка задумывалась не только для чатов. Она многофункциональна. Ее кодовое название — «движок для понимания разговоров и обучения на их основе» (CLUE), и она уже применяется во многих функциях Facebook*. Систему адаптировали для анализа обновлений статусов и ленты новостей. Социальные рекомендации тоже все чаще основываются на ИИ. Если вы напишете, например: «Еду в Омаху. Где там подают хорошие стейки?», ИИ, как ваш друг, оставит под этим постом комментарий со списком подходящих ресторанов и удобной картой. Если реальный друг ответит вам: «Там есть и отличные места для вегетарианцев», алгоритм сможет предложить и такие варианты.
Работа над намерениями для социальных рекомендаций в Facebook* пока ведется отделом Канделы, но, как и в случае с M Suggestions, в дальнейшем она выйдет за его пределы.
В конечном счете разработчики продуктов должны научиться работать с ИИ самостоятельно. «Сначала мы давали вам рыбу, — говорит Кандела, — теперь научили вас ее ловить. Но мы не остановимся на этом: мы построим рыболовецкое судно. А когда вы освоите и его, мы, видимо, начнем строить консервный завод!».
Сегодня примерно 70% работы с ИИ на платформе Facebook* ведет уже не отдел Канделы. Во многом это стало возможным благодаря упрощению доступа к нему. Некоторые инструменты, например Lumos, позволяют использовать машинное обучение даже тем, кто не умеет программировать.
Верховая езда и коробки с хлопьями
Lumos — ИИ компьютерного зрения, способный понимать, что изображено на фото в Facebook*, Instagram* и на других платформах. Его можно научить «видеть» что угодно. Он помог автоматизировать обнаружение и запрет порнографии и сцен насилия, незаконно используемых товарных знаков и логотипов и других нежелательных материалов. По фотографиям в вашей ленте новостей Lumos может определить, что вы любите и чем занимаетесь (чтобы показывать персонализированную рекламу и предложения).
Мне демонстрируют его работу: разработчики выбрали в качестве намерения «верховую езду». Интерфейс прост: несколько кликов мышью, несколько заполняемых форм («Что вы ищете?», «Какой нужен объем данных?») — и алгоритм начинает искать изображения. Страница заполняется картинками.
Ранее алгоритму уже поручали поиск такого контента, так что он неплохо справляется. Навскидку больше чем на 80% картинок действительно изображена верховая езда — причем картинки весьма разнообразны. Вот наездник и лошадь замерли, позируя. Вот конь встал на дыбы. А здесь он прыгает через препятствие. Алгоритм обучен находить очертания объектов и границы между ними, пользуясь ранее полученной информацией о том, что означают их соотношения. Он знает, что одно сочетание пикселей обычно означает человека, а другое — лошадь. И вот он «видит» одновременно человека и лошадь, причем человек расположен непосредственно над лошадью. Ага, решает алгоритм, это верховая езда.
Есть и картинки с другим сюжетом: на одной человек стоит возле лошади, на другом сидит на муле. Мы помечаем их как несоответствия, и машина добавляет к ним красную рамку, чтобы не повторять ошибок. Алгоритм усваивает новую информацию (добавляет ее к своей «справочной таблице») для будущего использования. Простая диаграмма наверху страницы показывает эволюцию точности и надежности алгоритма. Этот график всегда имеет S-образную форму: сначала обучение проходит медленно, потом резко ускоряется, чтобы затем, приблизившись к совершенству, вновь замедлиться. Да, находить верховую езду у алгоритма получается отлично.
Однако другие (потенциально очень полезные) изображения он анализирует хуже. Например, ему трудно распознать «квитанцию», ведь она выглядит почти как обычная печатная страница; однако если ИИ научится это делать, такой навык принесет немало пользы. Разработчики показывают мне, как дорожки для боулинга и эскалаторы «запутывают» алгоритм: у них много общего в форме и внешнем виде.
«А что, если попросить его найти “еду”?» — спрашиваю я. Это подводит нас к важному тезису: компьютер показывает то, чему его научили.
Мы просим алгоритм показать нам еду. Появляется множество фотографий фруктов и овощей, несколько тарелок с ресторанными блюдами. Все это еда. А вот коробка с хлопьями. Это еда?
В целом да. Или нет? Это же просто коробка. Но внутри все-таки еда. Когда мы покупаем эту вещь, мы покупаем еду, а не коробку. На вопрос, есть ли в шкафу еда, вы не ответите: «Нет, только коробка с хлопьями». (Если мыслить в контексте Facebook*, то, увидев фото коробки с хлопьями, ИИ должен считать, что это пост про еду или про коробку?) Но если рассматривать эту вещь как картинку, как единицу данных, то это изображение коробки.
Как же ее пометить: как соответствие или как несоответствие? Здесь машинное обучение превращается в искусство. При обучении алгоритмов нужно использовать очень четкие категории. Еда, конечно, слишком широкое понятие. Алгоритм наверняка допустит здесь немало ошибок. Лучше сузить запрос — например, до «овощей». Во время обучения каждый его участник должен понимать все термины одинаково. Представьте, что алгоритм обучают два человека, при этом один отмечает коробки с хлопьями как еду, а другой — как не еду. И так будут помечены терабайты данных!
То же относится к обработке естественного языка. Люди легко находят в тексте вторые и третьи смыслы. Например, я могу написать: «Отличный фильм про супергероев! Какой оригинальный сюжет! Хочу, чтобы они сняли еще сотню таких же». Друг, знающий меня и способный уловить иронию, сразу поймет, что я имел в виду противоположное тому, что написал. Искусственному интеллекту пока непросто вскрыть такой подтекст. Чтобы уловить иронию, ему придется пойти намного дальше простого анализа грамматики и словаря. Он должен знать, что я говорил и писал ранее, а также нащупать другие ключи, чтобы понять, действительно ли мне понравился фильм и я хочу посмотреть еще сто таких же или во мне говорит раздражение. Ошибка в подобном случае будет дорого стоить платформе, которая пытается «подружиться» со мной. Если я пошутил, а мне начнут настойчиво рекомендовать фильмы с супергероями, вряд ли я высоко оценю старания Facebook*.
Ловкость рук
В конце своего рассказа Хоакин Кандела приводит такие истории в подтверждение тому, что ИИ не всесилен, что его возможности зависят от воли людей и что главное — не придумать технологию, а научиться ее использовать. Тех, кто считает ИИ панацеей, он называет лентяями, не желающими разобраться в теме.
«Что меня бесит, — с горечью говорит он, — так это то, что все знают, что такое статистика, аналитика. Если я хочу просчитать реакцию на какой-то факт разных возрастных групп, я иду и обращаюсь к аналитику. А люди ничего этого делать не хотят, просто приходят и говорят: “Дайте-ка нам алгоритм машинного обучения, который сделает все вместо нас”. Я отвечаю: “Я вам что, волшебник? Сначала объясните, какую задачу вы решаете, какие цели ставите, на какие компромиссы готовы пойти?” Многие вообще впервые слышат о каких-то компромиссах. Если человек не может ответить на эти вопросы, я про себя думаю: “Как ты вообще себе представляешь искусственный интеллект?”».
Они считают это волшебством.
«Но это же не так! Я им объясняю: “Машинное обучение вам сейчас не нужно. Вам надо собрать компьютерщиков, обсудить проблему, проверить все на людях. Посидеть всем вместе, посмотреть на данные. Если вы сами не понимаете, что происходит, если даже мыслей никаких нет, если вы не можете выстроить даже простейшую систему правил типа “если человеку меньше 20 лет и он живет там-то, ему нужно то-то”, — то даже обсуждать применение ИИ к вашей проблеме бессмысленно».
С другой стороны, приятно, когда человек начинает разговор не с технологий, а с проблемы, которую они с коллегами уже очень глубоко изучили. Ведь иногда — я бы даже сказал, часто — если у вас есть нужный набор данных, на 80% вашу проблему может решить старая добрая экспертная система на основе правил. И знаете, в чем ее преимущество? Ее поймет любой дурак. В общем, главное — сначала приложить к проблеме голову».
Об авторе. Скотт Беринато — старший редактор HBR, автор книги «Good Charts: The HBR Guide to Making Smarter, More Persuasive Data Visualizations» (2016).
* принадлежит Meta, которая признана в России экстремистской и запрещена