






Будущее нейросетей
Какие глобальные тренды в развитии GPT существуют?
Сейчас очень популярными становятся мультимодальные модели, которые обучены работать с несколькими источниками данных — например, текстом и изображением. Они позволяют решать новые задачи, где нужно учитывать разные типы информации одновременно, такую модель, к примеру, можно попросить что-то на этом изображении изменить или описать его.
В сервисах «Яндекса» уже появляются первые функции, связанные с мультимодальностью. Нейросеть уже сейчас позволяет загрузить в нее изображение и что-то про это изображение уточнить. Например, если вы не знаете название растения, можно его сфотографировать и спросить, как за ним ухаживать.
Мультимодальные модели активно применяют и в бизнесе, в том числе в решении задач, связанных с поддержкой. Многие пользователи смогут отправить изображение ошибки или проблемы, и мультимодальная модель способна в перспективе решить проблему.
Приведет ли развитие нейросетей к исчезновению каких-то профессий?
Предсказать я это не могу, но думаю, что правильнее сказать так: профессии не исчезнут, а эволюционируют. К примеру, если раньше поиск информации или написание текстов подразумевал работу с определенными устройствами, то сейчас и в проверке орфографии, и в написании корректных текстов нейросети помогают и, соответственно, снижают барьер для входа в профессии. Модели становятся умнее и повсеместно внедряются в разные продукты, а значит, во все большем количестве профессий умение с ними работать будет критерием конкурентоспособности.
Если мы говорим про генеративные модели работы с текстом, любая профессия, где есть большое количество подобной работы и рутины, в ближайшие несколько лет будет видоизменена. По данным исследования «Яков и партнеры» , активное использование GPT ждет в первую очередь профессии, которые обрабатывают большое количество информации, — это маркетологи, рекрутеры, юристы и бухгалтеры. Затронет это и IT-сектор, где очень большое количество задач связано с модерацией текста или работой с теми же отзывами. Зарубежные компании сейчас, помимо прочего, занимаются автоматизацией работы программистов. Мы следим за зарубежными решениями, которые показывают экономическую эффективность подобных направлений, — например, Codeium и GitHub Copilot . Язык кода тоже подвластен языковым моделями для оптимизации, предсказания и помощи в режиме co-pilot.
YandexGPT
На базе каких технологий создана YandexGPT ?
Технологии языковых моделей развиваются по сложному пути. Многие исследовательские лаборатории представляют свои архитектуры для создания больших языковых моделей. Например, архитектура трансформеров, впервые представленная Google, стала основой для моделей OpenAI, и по ее образу созданы многие языковые модели , включая YandexGPT . Но обучена YandexGPT полностью на собственных фреймворках, то есть с использованием собственного ПО и собственных алгоритмов и оптимизаций обучения модели.
Архитектура нейросети — это структура и организация слоев и нейронов в искусственной нейронной сети, которая определяет, как данные проходят через сеть и как производится их обработка. Архитектура трансформеров является одной из наиболее распространенных, на ее основе созданы такие модели, как GPT, BERT и проч.
Как «Яндекс» адаптировал под себя эту архитектуру?
Процесс обучения модели делится на три этапа: pre-train, fine-tuning и alignment. Сначала модель обучается языку, учится формулировать логически правильные предложения. На этом этапе модель обучается на огромном массиве данных. Обучаясь, она запоминает много фактов об устройстве нашего мира. На следующем этапе ее учат решать конкретные задачи — такие, например, как генерация текста по заданной инструкции. Мы обучаем свою модель с нуля на всех трех этапах, не используя готовые решения. Нейросети научились понимать язык и генерировать текст таким образом, что его уже сложно отличить от того, что написал человек.
Каковы ключевые сценарии использования YandexGPT ?
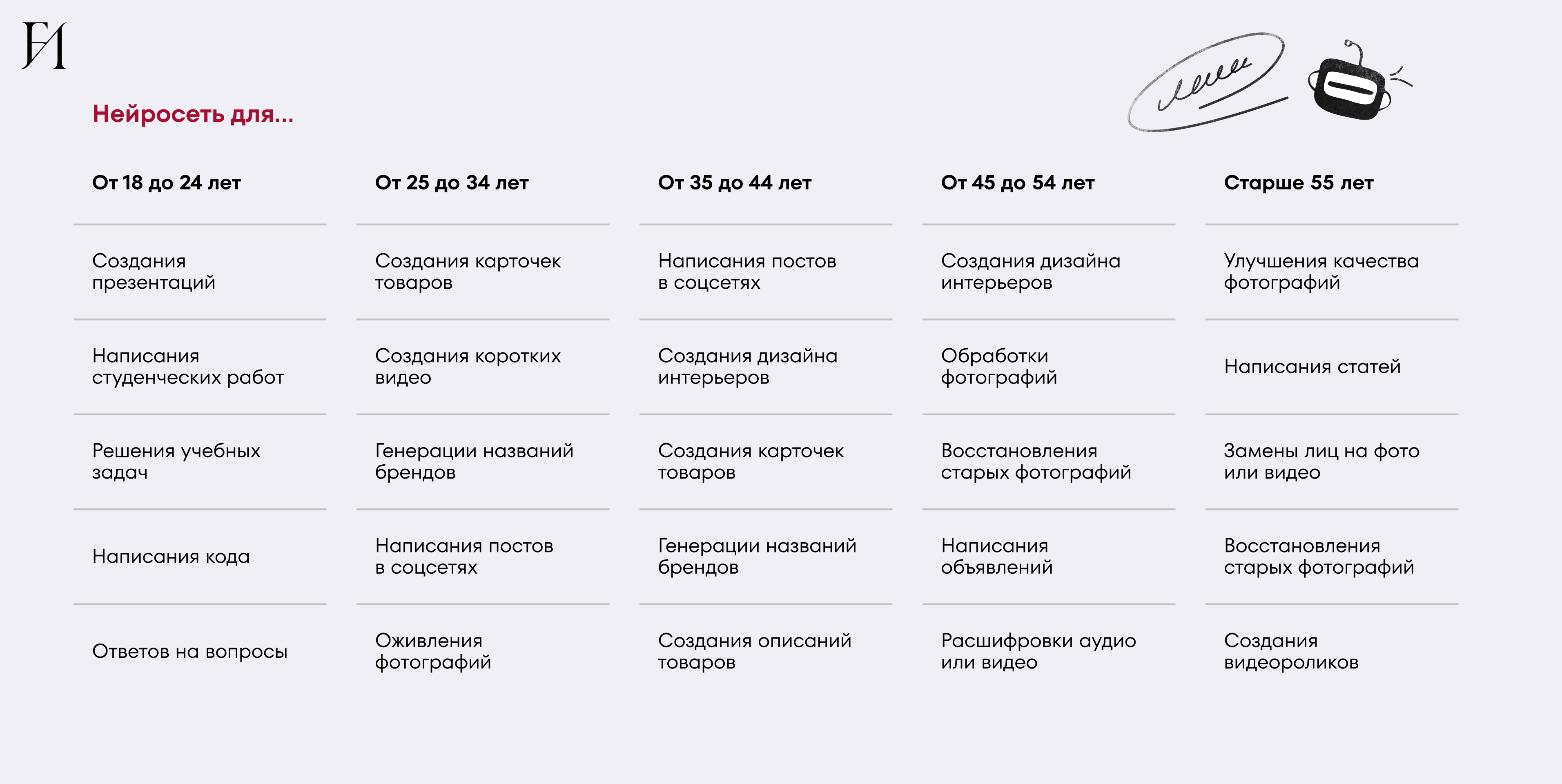
Генеративные нейросети для работы с текстом в 65—70% применяются для рабочих задач — например, для создания описаний товаров или составления рекламных объявлений. Остальные сценарии — творческие задачи или развлечение: например, нейросеть поможет сочинить сказку или стишок для игры с ребенком. Востребованы и образовательные задачи — скажем, помощь в создании презентаций или решении задач.

Чем отличаются модели GPT между собой?
Есть определенная специфика в том, как оценивать качество моделей и по каким задачам. Например, если мы посмотрим на известные способы сравнения моделей за рубежом, то можно вспомнить разные бенчмарки — например, MMLU (Multi-task Language Understanding) , который включает 57 тем, характеризующих, насколько нейросети хорошо разбираются в разных сферах знаний и могут решать разные задачи.
В России есть площадка LLM Arena, позволяющая оценить, насколько хорошо модели отвечают на вопросы пользователей на русском языке . Там экспериментальная версия YandexGPT последнего поколения занимает достаточно высокую позицию.
Как интеграция GPT в поиск повлияет на пользовательское поведение и метрики? Что изменится для пользователей и для вас?
Речь идет фактически про новые сценарии поиска, которые предлагает наш новый сервис « Нейро » . Одна из главных функций нейросетей — помочь пользователям освободиться от части рутины. Например, если пользователь ищет в поиске информацию на сложную тему, которая требует прокликать какое-то количество ссылок, сравнить информацию, вникнуть во все аспекты запроса. « Нейро » же делает это самостоятельно — изучает большой объем данных в интернете и формулирует ответ. Мне кажется, это поможет не только пользователям, но и в целом расширит возможности поиска — позволит решать задачи, которые требуют обработки большего количества информации.
Что получает от этого «Яндекс» ? Увеличение времени, проведенного пользователем в поисковике, и, следовательно, рост доходов от контекстной рекламы?
Не совсем так. Ответ « Нейро » всегда содержит ссылки на источники, на основе которых был составлен. Это нужно, чтобы пользователи могли получить дополнительные подробности по интересующей теме, а площадки — переходы на сайт.
Если задуматься про качество продукта поиска, то чем оно выше, тем пользователь быстрее решает свою задачу, проводя меньше времени в поисковике, соответственно. Если какое-то решение удобно и дает новые сценарии для решения задач, то пользователи возвращаются к нему. Например, обычным поиском « Яндекса » пользуются порядка 100 млн человек ежедневно, из них уже воспользовались « Нейро » более 9,5 млн. Текущий продукт « Нейро » не имеет пока конкретной модели монетизации — мы проверяем различные гипотезы и, конечно же, в первую очередь рассматриваем те сценарии, при которых сервис станет доступен всем пользователям ( сейчас « Нейро » доступен в мобильном приложении « Яндекс с Алисой » и в « Яндекс Браузере » по авторизации в « Яндекс ID » — прим.редакции ) .
ИИ для бизнеса
Как вы собираетесь выводить YandexGPT на В2В-рынок, что вы будете предлагать бизнесу?
YandexGPT уже доступна по API для внешних бизнесов. Это очень важная тема для « Яндекса » , потому что и для компании, и в целом для индустрии развитие языковых моделей требует больших инвестиций. Если смотреть на перспективу, думаю, наибольший экономический эффект можно ожидать в ближайшие несколько лет от, конечно же, применения нейросетей в различных бизнес-процессах.
В сентябре 2023 года мы с « Яков и партнеры » ( компания, созданная командой McKinsey в России — прим. редакции ) провели исследование, которое показало, что представители порядка 60% различных профессий смогут автоматизировать рутинные задачи с помощью YandexGPT. В тот момент мы приняли решение проработать эти сценарии. Если посмотреть, где в ближайшем будущем применение нейросетей будет наиболее оправдано, то в топе будет отрасль поддержки. Среднестатистический оператор примерно 40% времени тратит на то, чтобы найти по задаче пользователя нужный документ, где написано, как эту задачу можно решить, а еще 20% — он планирует ответ: пишет его, ведет диалог с пользователем. Именно это уже хорошо получается у наших моделей и технологий.
В индустрии уже есть такое понятие — co-pilot, второй пилот, который сидит рядом и помогает часть рутины взять на себя. И уже сейчас мы видим первый эффект: благодаря подобным нейросетевым подсказкам нам удается сократить более 10% времени для операторов поддержки на наших внутренних сервисах, тем самым высвободив время для большего количества задач и для решения более сложных вопросов. Планируем представить этот инструмент и для внешних бизнесов.
В английском появился термин bot shit, который описывает ситуацию, когда нейросеть, подменяющая специалиста поддержки, начинает « галлюцинировать » и выдает неверный ответ. Как вы планируете решать эту проблему?
Даже самые продвинутые языковые модели могут ошибаться из-за вероятностной специфики генерации ответов. Модель, генерируя ответ, взвешивает вероятности при написании текста и старается угадать наиболее вероятный ответ. В большинстве случаев, если модель большая и обученная на хорошем датасете, у нее получается оперировать фактами и запоминать их, работать с некоторым инструментарием — например, суммаризовать статью, не придумывая факты. Но если модель не может решить эту задачу, есть вероятность, что она этот ответ может придумать и сгенерировать его случайным образом. Это часто и называют эффектом галлюцинации.
В наших продуктах мы минимизируем ошибки благодаря тому, что мы размечаем с помощью наших асессоров, AI-тренеров, а также точечно дообучаем модели не совершать эти ошибки. Также поверх ответа модели можно добавлять фильтрацию, если ответ оказался неправильным или неподтвержденным.
Такие фильтрации могут также работать в В2В: например, если говорить про подсказки операторам поддержки, мы можем показывать эту подсказку только тогда, когда мы уверены в ответе, и проверять дополнительно отдельно обученной моделью, соответствует ли эта подсказка инструкции, которую модель получила. С увеличением качества модели будет уменьшаться количество ошибочных ответов, подсказки станут приходить чаще и лучше автоматизировать работу оператора.
Как «Яндекс» предоставляет доступ к GPT для сторонних сервисов? Как интегрирует в собственные продукты?
Продукты YandexGPT могут внедряться двумя способами. Первый — это API, доступное через « Яндекс Облако » , где оплата взимается за количество токенов в запросе и количество самих запросов. Компании могут самостоятельно интегрировать эту технологию в свои процессы, настраивая ее под свои нужды и масштаб использования. Второй способ — использование готовых технологических решений, таких как автоматизация поддержки.
Сервисы « Яндекса » сами могут решать, где эта технология будет применяться эффективно, и разрабатывать на этой основе собственные решения. Например, команды « Яндекс Авто » и « Яндекс Маркета » не так давно внедрили версии YandexGPT, позволяющие создавать описание для объявлений и товаров. Эта функция прижилась, ей активно начинают пользоваться авторы объявлений.
Для внешней аудитории мы экспериментируем с доступом к различным моделям YandexGPT в рамках корпоративного браузера. Многие работники в различных индустриях занимаются своими задачами именно в браузере — просмотр резюме, написание текстов. И мы видим, что, если модели нативно интегрированы прямо в рабочую среду, это дает наибольший эффект.


